How SurveyMonkey gets its data
We ask survey questions on an unmatched scale to get high-quality data.
Every day, over 2 million people have conversations using SurveyMonkey.
They’re not just customers, employees, market researchers, or event attendees—people across the world use SurveyMonkey to give feedback on anything you can imagine. We ask just a tiny fraction of those people for their opinion on important issues, and get unprecedented access to a sample of the U.S. population.
That access lets us poll the American public for their views on important current events, while our team of expert survey scientists make sure the sampling of individual units matches the U.S. population at large.
How does SurveyMonkey get its data? We’ll take you through it, step by step.
1. Over 2 million people take surveys on SurveyMonkey’s platform each day.

2. A random selection of those people are invited to participate in a survey.

3. After they’ve taken the survey, we filter out people who didn’t complete it (nonresponses).

4. Our survey scientists carefully adjust the data so that it’s representative of the sample population.
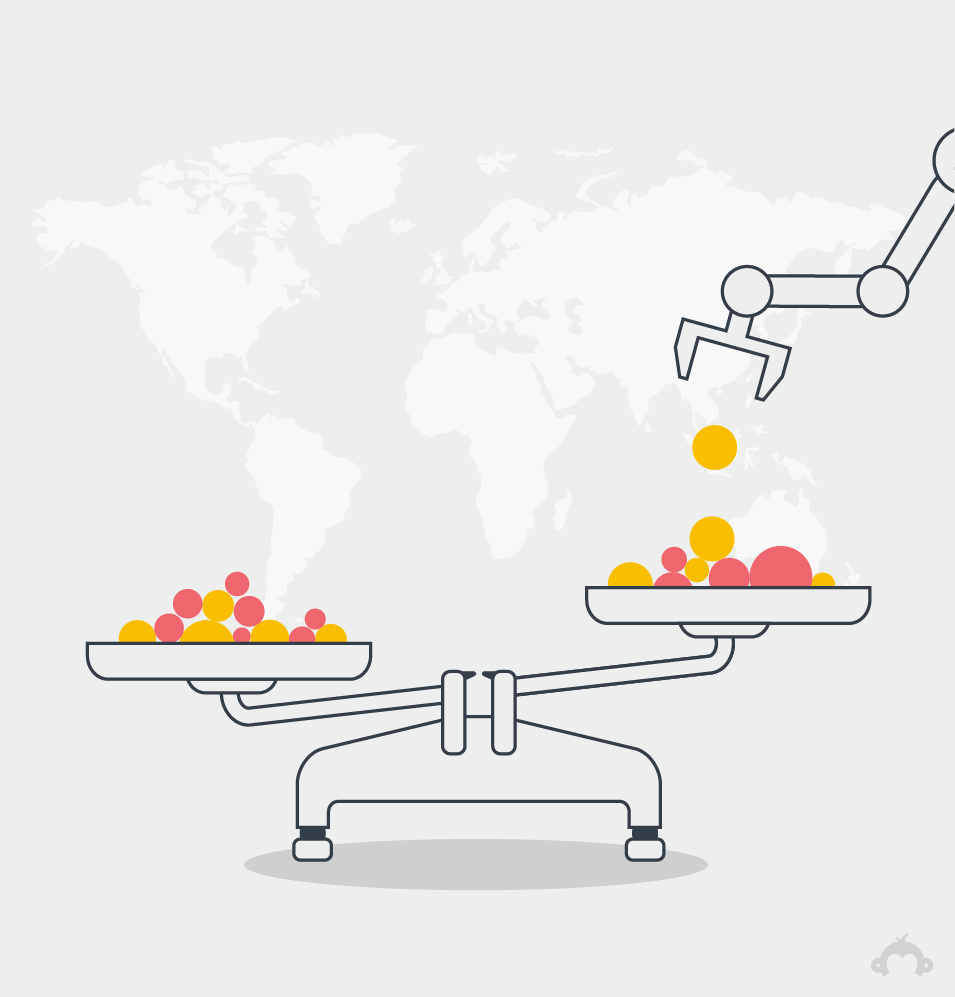
5. What does that mean? When groups in our sample don’t exactly match the larger population, we use advanced statistical inferences to balance them.

6. Now we start looking at the results. We aggregate and compile responses to provide an easy-to-understand snapshot of what people are thinking.
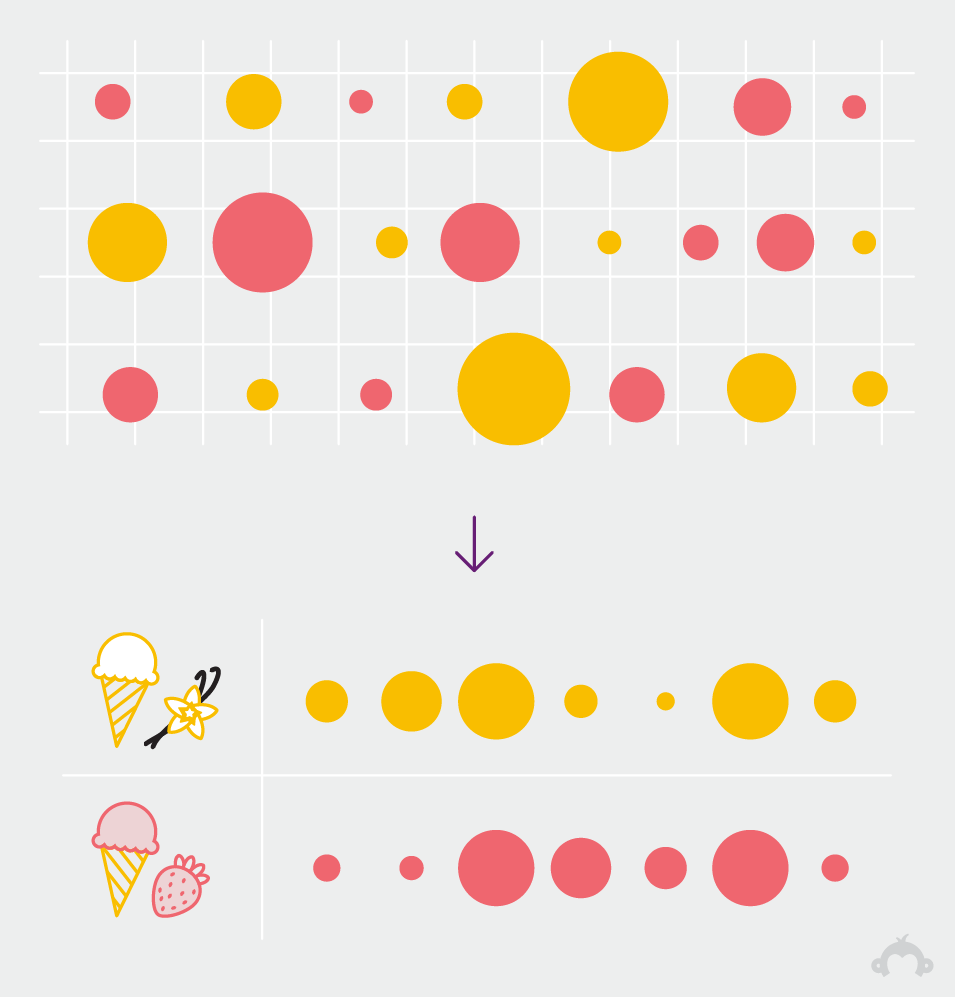
7. The large scale of our sample allows us to pinpoint views that others cannot, giving us an inside look on public opinion and experiences.

Why you can count on SurveyMonkey’s data
Our team of survey methodologists and pollsters stand behind our data because of three core principles:
Scale and Diversity: During the millions of survey conversations we have each day, we talk to people from a broad range of demographic groups—doctors under 30, construction workers in Maine or Asian American retirees. We have respondents from every:
- Area of the U.S. (even to state level)
- Age, gender, ethnicity
- Background (income, job role, political affiliation)
Known Sampling: Unlike some, we don’t take personal information from our respondents—we ask for it. We collect demographic information on all our respondents, which provides important context for our results. It also allows for more sophisticated weighting of our data, making it even more accurate.
SurveyMonkey’s polling methodology
Our SurveyMonkey research team runs surveys every day on politics, sports, current events, the media, and whatever else piques our curiosity. We surveyed more than 1 million voters over the course of 2016, and we haven’t really slowed down since—though we have modified our methodology slightly. This page is a resource for anyone interested in our current sample design, questionnaire, weighting methodology, and data availability—read on!
*If you’re interested in our 2016 Election Tracking methodology you can always visit this link.
Who do we survey?
Over 2 million people take user-generated surveys on the SurveyMonkey platform each day. We select a random sample of these respondents to take part in our research surveys. After completing their initial survey, they see a “thank-you” page inviting them to take an additional survey—those are our research surveys that we conduct in partnership with media outlets and other organizations.
Our sampling process is similar to the way polling has traditionally been done, but updated for the internet age. Instead of randomly drawing respondents from a list of phone numbers, we randomly draw from our diverse base of daily survey takers. We ask our respondents how old they are, whether they are registered to vote, what state they live in, and so on… just as phone polls do.
Our survey-takers come from all 50 states—urban, suburban, rural, and everything in between. Because SurveyMonkey is an online platform, all respondents must have internet access in order to complete our surveys. However, this is becoming less of a limitation as internet penetration increases and as more respondents complete surveys on their cell phones or mobile devices.
What questions do we ask?
SurveyMonkey’s research surveys are in the field continuously; we have respondents completing surveys 24 hours a day, 7 days a week. All surveys are written in English, though we occasionally translate into Spanish as well. We always ask respondents for information on their sex, race/ethnicity, age, state, and education level so that we can use this data to weight our results to be nationally representative.
We routinely include questions on party identification, presidential approval, and respondents’ most important issue so that we can track changes to these questions regularly. If multiple surveys are running at once, we aggregate responses to these questions. There is no risk that any preceding questions on different surveys will influence respondents’ answers because these questions are always asked first.
How are the results weighted?
We have several weighting schemes that we can choose to deploy depending on the sample size and the population of interest for each survey. For each of the weighting schemes outlined below, we use the Census Bureau’s 2015 American Community Survey (ACS) to generate estimates that reflect the most up-to-date demographic composition of the US in terms of age, race, sex, education, and geography. We require all respondents to answer the survey questions used to weight these parameters in each of our surveys.
- National general population weighting (default)
When tabulating national estimates for surveys with fewer than 10,000 respondents, we perform multi-stage raking to construct national weights. We first define state/division geographic units according to state-level population sizes and Census division classification. States with more than five million residents are defined as stand-alone units, while smaller states are grouped together within a Census division to form secondary geographic units. At the first stage of raking, the sample is weighted to adult population sizes of state/division geographic units to generate initial weights. The second stage of raking adjusts the initial weights by gender, age, race, and education within each Census region to match targets obtained from the ACS. - National general population weighting — large samples
When a national survey has more than 10,000 respondents, we perform multi-stage raking to construct national weights. At the first stage of raking, the sample is weighted to adult population sizes of 50 states plus the District of Columbia to generate initial weights. The second stage of raking adjusts the initial weights by gender, age, race, and education within each Census region to match ACS targets. - State-level weighting
For surveys that focus on one particular state, such as the our surveys just prior to the special elections in Alabama, Virginia, and New Jersey in 2017, we employ raking to construct state-level weights. We first classify postal zip codes into five groups according to their population sizes. We derive initial respondent weights from estimated sampling rates on the SurveyMonkey News “thank-you” page within each zip code group. We then rake the initial respondent weights by gender, age, race, and education within the state to match targets obtained from the ACS. - Region-level weighting
For surveys that focus on a region of the United States, such as our southern states polling for NBC, we employ multi-stage raking to construct region-level weights. We first define state/division geographic units according to state population sizes and Census division classification within the sampled region. States with more than five million residents are defined as stand-alone units, while smaller states are grouped together within a Census division to form secondary geographic units. We then classify postal zip codes into five groups according to their population sizes within each geographic unit. We derive initial respondent weights from estimated sampling rates on the SurveyMonkey “thank-you” page within each zip code group. At the first stage of raking, the initial weights are controlled to geographic unit population sizes. The second-stage raking adjusts first-stage weights by gender, age, race, and education to match ACS targets for the geographic unit.
What’s our margin of error?
Surveys that use probability-based designs can calculate and report a margin of error estimate for each statistic they produce. You’ll often see language such as “this poll has a margin of error of +/-3.5 percentage points,” which means that if the difference between two estimates is within the margin of error, we can’t tell with confidence which one is greater.
SurveyMonkey research surveys do not have a probability-based design, because there is no well-defined sampling frame of respondents to SurveyMonkey surveys. Therefore, to avoid confusion, we do not report a margin of error term. Instead, we utilize a “modeled error estimate” which is calculated using a bootstrap confidence interval. According to the American Association for Public Opinion Research (AAPOR), this method is a best practice for non-probability surveys, as it “approximates the variance of a survey estimator by the variability of that estimator computed from a series of subsamples taken from the survey data set.”
Here’s an example of our typical methodology summary:
This SurveyMonkey online poll was conducted Jan. 5-6, 2017 among a national sample of 1,725 adults ages 18 and up. Respondents for this survey were selected from the nearly 3 million people who take surveys on the SurveyMonkey platform each day. Data for this week have been weighted for age, race, sex, education, and geography using the Census Bureau’s American Community Survey to reflect the demographic composition of the United States. The modeled error estimate for this survey is plus or minus 3.5 percentage points. For full topline results, see here.
Here, the modeled error estimate of plus or minus 3.5 percentage points has the same interpretation as the margin of error example above. In every blog post or report, we’ll always include the dates during which the survey was in the field, the total number of respondents, a brief description of our weighting methodology, and the modeled error estimate for the survey.
Note: Because we are an online survey organization, people often assume that our research surveys are administered to a non-probability panel. This is incorrect. While SurveyMonkey does maintain a panel of respondents to make available to customers, we seldom employ this panel for respondent recruitment. Our methodology statement will always indicate the way we obtained our sample of respondents and weighted our results.
Where can I get the data?
If you’d like to keep up with our ongoing insights, here are a few ways to do that:
Trump approval: Every Friday we publish a week’s worth of data on President Trump’s approval rating. View the archive here.
Consumer confidence: We publish an index of consumer confidence based on questions about individuals’ current financial health and their expectations for the future. View the archive here.
Small business confidence: Every quarter, in partnership with CNBC, we ask small business owners about the current small business environment and their expectations for the future. View the archive here.
Partners: We have more partnerships now than ever before. Check out recent results published by NBC News, Axios, FiveThirtyEight, The New York Times, ESPN, Vanity Fair’s Hive & theSkimm, OZY and CNBC.
Want to ask people about the issues that matter to you?
SurveyMonkey Audience is a separate tool with a different method for recruiting respondents. In Audience, respondents take surveys in exchange for donations to charity and customers can pay to hear their opinions. The polling method described on this page isn’t available for purchase. It’s the perfect tool to use to get research for concept testing, content marketing, and more.
Who’s behind the research?
SurveyMonkey employs a team of survey methodologists—scientists who study surveys, polling, public opinion, and data collection. They know exactly how to structure surveys, ask questions, and analyze data in order to get precise results.
Tutustu muihin materiaaleihin

Insights Manager
Insights managerit voivat toimittaa näiden työkalujen avulla kiinnostavia ja käyttökelpoisia havaintoja sidosryhmien tueksi ja tavoittaa uusia kohdeyleisöjä.

Tutustu SurveyMonkeyn kuluttajatuote- ja ‑palveluratkaisuihin
Kuluttajatuotteiden ja ‑palveluiden toimialalla, kuten matkailussa ja majoituksessa, muokataan tulevaisuutta SurveyMonkeyn avulla.

Tutustu SurveyMonkeyn vähittäismyyjille suunnattuihin ratkaisuihin
Katso, miten SurveyMonkey auttaa vähittäismyyntiyrityksiä selvittämään muuttuvia markkinatrendejä, kehittämään ilahduttavia tuotteita ja rakentamaan suosittuja brändejä.

Tutustu SurveyMonkeyn palveluyrityksille suunnattuihin ratkaisuihin
Katso, miten palveluorganisaatiot hankkivat asiakas‑ ja markkinatietoja SurveyMonkeylla.